Print PDFs using HTML+CSS

The Portable Document Format (PDF), introduced in 1993 by Adobe, revolutionized document sharing by providing a freely available specification. This milestone coincided with other pivotal moments in tech history, including Tim Berners-Lee and CERN's release of the royalty-free Web protocol and the birth of Netscape Navigator and the Intel Pentium processor. Three decades later, PDFs from that era remain readable, akin to printed pages.
In all that time PDFs proofed to be a replacement for exactly that: Printed Paper. In today's digital landscape, they serve as versatile documents for archiving, signing, and sharing information among individuals. At the core a PDF a storage container combined with a subset of the PostScript page description programming language but in declarative form, for generating the layout. It contains all graphics, fonts and even javascript in newer versions.
Options to create PDFs
When it comes to generating or "printing" these documents, specialized software is required. While most devices offer a built-in PDF printer, server side or custom software solutions often require the use of specific libraries. These libraries, widely recognized in the industry, can be categorized as follows:
| Name | Category | Description |
|---|---|---|
| IText / OpenPDF, Apache PDFBox | API | Imperative programming approach to create PDFs by defining the sequence of operations required to create a PDF document, such as adding text, images, shapes, and other elements. |
| Apache FOP, Antenna House (commercial) | XSL-FO + XML | Declarative definition of a document of the layout using XSL-FO. This W3C standard describes the formatting of XML documents for print |
| JasperReports | Tool + XML | Uses a visual editor to create a .jrxml file that is a xml based declarative way to define the document. Java is used to read and process data and customize the output further. |
| Weasyprint, paged.js, Prince XML, | HTML + CSS paged media | Declarative definition of a document using HTML and CSS. It relies on the W3C Standard print media rules, print specific properties and print units such as inch or centimeter. |
Comparison
The code speaks for itself. The task is to create a PDF document with a centered Text "Hello PDF World" on it.
OpenPDF
import com.lowagie.text.Document; import com.lowagie.text.Element; import com.lowagie.text.Paragraph; import com.lowagie.text.pdf.PdfWriter; import java.io.FileOutputStream; public class SimplePDFCreator { public static void main(String[] args) { try { Document document = new Document(); PdfWriter.getInstance(document, new FileOutputStream("hello_pdf_output.pdf")); document.open(); Paragraph paragraph = new Paragraph("Hello PDF World"); paragraph.setAlignment(Element.ALIGN_CENTER); document.add(paragraph); document.close(); } catch (Exception e) { e.printStackTrace(); } } }
FOP
<fo:root xmlns:fo="http://www.w3.org/1999/XSL/Format"> <fo:layout-master-set> <fo:simple-page-master master-name="A4" page-height="29.7cm" page-width="21.0cm" margin-top="2cm" margin-bottom="2cm" margin-left="2cm" margin-right="2cm"> <fo:region-body margin="0"/> </fo:simple-page-master> </fo:layout-master-set> <fo:page-sequence master-reference="A4"> <fo:flow flow-name="xsl-region-body" text-align="center"> <fo:block>Hello PDF World</fo:block> </fo:flow> </fo:page-sequence> </fo:root>
Weasyprint
<!DOCTYPE html> <html> <head> <style> @page { size: A4; margin: 0; } body { margin: 0; padding: 0; display: flex; justify-content: center; align-items: center; height: 100vh; font-family: Arial, sans-serif; } </style> </head> <body> <div>Hello PDF World</div> </body> </html>
Exploring the Advantages of HTML + CSS for PDF Generation
Over the years, we've explored all these approaches in different projects, each with its own benefits and drawbacks. When it comes to creating PDFs, we've found the HTML+CSS approach lately to be particularly advantageous for the following reasons:
-
Knowledge: Given our extensive familiarity with HTML and CSS, investing in further knowledge of CSS proves to be beneficial. Leveraging this existing expertise streamlines the PDF creation process.
-
Control: Developers have the ability to finely adjust the appearance of elements using HTML and CSS, utilizing familiar tools and techniques. This level of control ensures the desired outcome in document styling.
-
Flexibility: HTML defines the content structure, while CSS dictates its visual presentation. This separation allows for flexible development workflows. HTML data can be generated in various ways, including templating engines like Mustache or server-side rendering. Additionally, stylesheets can be developed concurrently with HTML creation, facilitating a cohesive fast design feedback loop.
Case study: web portal
For an interactive public web portal, the client demanded well-formatted downloadable PDFs for every displayed web page (about 5000). Relying solely on the print stylesheet and the system's PDF print function was impractical due to inconsistent output across devices, the inability to test the results effectively and very special requirements for the print output. The team was proficient in the web area and so we wanted to leverage this advantage.
We decided to generate PDFs using a generic converter service with templates based on HTML, CSS and mustache was logicless template language. A service would take a template, the data and return a PDF. To achieve this, we chose a headless CMS to store each webpage as structured JSON content, not HTML. A headless CMS is a content management system that stores and delivers structured data through an API for a user defined model as well as unstructured data from a file storage. Therefor it didn't dictate how content is presented or displayed.
Example of a welcome page entity in the headless cms used as data source for web and pdf.
{ "meta": { "language": "de" }, "content": [ { "__component": "SearchInput" }, { "richText": "<h1>Welcome</h1>", "__component": "RichText" }, { "__component": "teaser", "colorSchema": "red", "text": "<p>Weiterbildung gesucht? Wir helfen Ihnen, ein passendes Weiterbildungsangebot zu finden. Und zwar ganz unabhängig davon, ob Sie sich beruflich oder persönlich verändern bzw. weiterentwickeln wollen oder ob Sie über das Abitur oder einen Hochschulabschluss verfügen.</p>", "headlineLevel": 2, "subHeadlineLevel": 5, "subHeadline": "Suchen. Finden. Weiterbilden.", "headline": "Weiterbildung an Hochschulen", "picture": { "src": "/cms/api/download/medium_Wasist_WWB_geschnitten3000x1122_8c45694435.jpg", "type": "image", "caption": "Wissenschaftliche Weiterbildung für alle Altersklassen ", "description": "Wissenschaftliche Weiterbildung für alle Altersklassen " } } ] }
This page entity listed above consisted of various modules with specific properties, a search input, a formatted richtext containing HTML and a teaser module with headlines, subheadlines, and an image URL. The website generator utilized this information to create the interactive webpages based on React and a given stylesheet. Each module matched a react component.
For the PDF generation we observed the page publish event in the backend page editor. The event triggered the process to fetch the data and send it along with a template (chosen by the type of page entity) to the generic converter service. This service then transformed the webpage content into a PDF file. The result was stored within the headless CMS as binary asset next to the page entity. The template defined the rules how modules were styled, for example did we decide to hide the interactive search input, display the richtext was rendered as pure HTML and the teaser module in a very different paper styled version than the web.
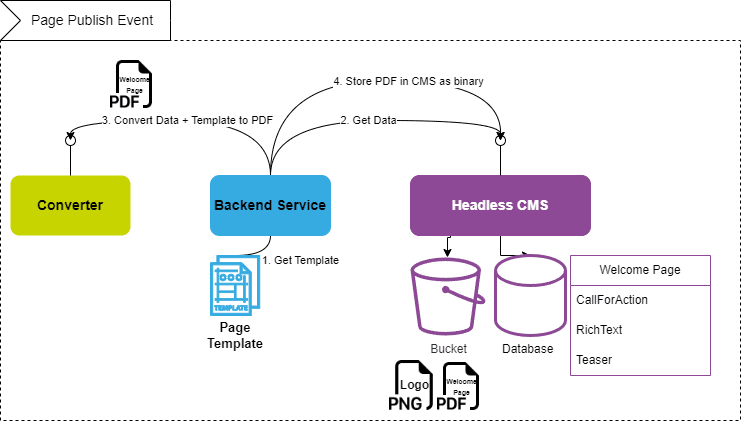 ;
;The following sections provide a breakdown of how this solution was implemented, covering each step from developing a converter service, developing templates and testing the PDF generation.
Generic converter service
We chose Weasyprint because it is an open source project and doesn't rely on any browser engines making it platform independent. It is written in python, so we created a REST API using flask and packaged it in a docker container.
The requirements.txt contains the dependencies:
gunicorn==20.0.4 flask==1.1.4 flask-request-id-header==0.1.1 markupsafe==2.0.1 flask-cors==3.0.0 boto3==1.9.22 WeasyPrint==52.5 # HTML & CSS to PDF chevron===0.13.1 # Mustache PyPDF2==1.26.0 # merge PDFs
The server wsgi.py itself offers a post method to receive a JSON with data, html and css (the template). The method processes the data using mustache to create the final and combines it with the css stylesheet into a PDF using the WeasyPrint api. The result is returned as application/pdf content type binary.
#!/usr/bin/env python import json import os import logging from functools import wraps import chevron from flask import Flask, request, make_response, abort, has_request_context from flask_request_id_header.middleware import RequestID from io import BytesIO from PyPDF2 import PdfFileMerger, PdfFileReader import base64 from weasyprint import HTML, CSS from weasyprint.fonts import FontConfiguration from json2xml import json2xml from json2xml.utils import readfromjson import pandas as pd app = Flask('converterService') app.config['REQUEST_ID_UNIQUE_VALUE_PREFIX'] = 'XY-' RequestID(app) @app.route('/pdf', methods=['POST']) @authenticate def generatePDF(): name = request.args.get('filename', 'unnamed.pdf') # Request is a JSON (HTML + CSS) if request.headers.get('Content-Type') == 'application/json': app.logger.info('Received JSON as POST-Request') json_data = json.loads(request.data.decode('utf-8')) html_str = json_data['html'] css_str = json_data['css'] if 'data' in json_data: html_str = apply_template(html_str, json_data['data']) font_config = FontConfiguration() html = HTML(string=html_str) css = [CSS(string=css_str, font_config=font_config)] pdf = html.write_pdf(stylesheets=css, font_config=font_config) response = make_response(pdf) response.headers['Content-Type'] = 'application/pdf' response.headers['Content-Disposition'] = 'inline;filename=%s' % name app.logger.info('"Successfully created pdf: %s' % name) return response ...
Template
We chose to create logic-less encapsulated templates using Mustache to make the templates more robust and testable. These templates were organized as a npm package, with versioned releases. The PDF-generating backend-service defined the template as dependencies in the package.json file.
The most simple template contained a single ìndex.js file responsible for loading the html and css file and preparing the data. Although the logic-less nature is great for writing templates, it doesn't allow any logic inside the template. Thats why we added a function to process the data beforehand. The function was used to process the data to match the templates requirements, e.g. sorting, data multiplexing, checking for value definition and storing it as boolean value and using i18n bundles. The result was used as test data in the development of the template styling.
const fs = require("fs/promises"); /** * Loads the files of the template. Provides the html and css * @returns {html, css} defining the template */ module.exports.loadFiles = async () => { const loadHtmlPromise = fs.readFile(`${__dirname}/template.html`); const loadCssPromise = fs.readFile(`${__dirname}/template.css`); const [html, css] = await Promise.all([loadHtmlPromise, loadCssPromise]); return { html, css }; } /** * Process the given data into a returned object that will be used in the template. * @param {string} langCode the iso 636 languageCode like 'de' or 'en' * @param {data} data defined as contract between producer and consumer * @returns an object containing the processed data that can be used in the template */ module.exports.processData = async (langCode, data) => { const processedData = Object.assign({}, data); processedData.entries.forEach((element: any) => { if (element["compareIds"]) { element.isCompare = true; element.compareString = element.waTitles.join(", "); } }); return processedData; }
Some unprocessed example data:
{ "id": "262cca1c-44c1-4fc4-8dd4-93f25cfa413c", "name": "My Comparison", "userCode": "VKuWM", "__typename": "Bookmark", "entries": [ { "entryName": "Comparison of Data", "entryDescription": "Comment", "favorite": false, "slug": "/compare/?id=101144&id=128291&id=107137", "compareIds": [ 101144, 128291, 107137 ], "daTitles": [ "Civil-Military Interaction", "Change Management", "Communication" ], "__typename": "BookmarkComparison" } ] }
The html is using mustache as templating language for most of the data like labels and content.
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Document</title> </head> <body> <header> ... </header> <link rel="stylesheet" href="../../pdf-styling/build/index.css" /> <div id="bookmarks" class="container"> <!-- Relevant information about the search --> <section class="bookmarksInfo"> <h2>{{translations.title}}</h2> {{#userCode}}<span>Usercode: {{userCode}}</span>{{/userCode}} <h3>{{name}}</h3> ... </section> </body> </html>
The CSS closely resembles a web app, naturally incorporating page-specific definitions, and employing a familiar page size, which simplifies shape measurement.
@use "../variables" as *; #info { padding: 0 $contentPadding; max-width: 100%; break-inside: auto; .row { z-index: 1; display: flex; flex-wrap: nowrap; justify-content: space-between; gap: 0.5cm; margin-bottom: 0.5cm; break-inside: auto; .column { width: 47%; } } table { height: fit-content; width: calc($a4width - 22mm); // calc($a4width - $contentPadding * 2); not working because of mixe units border-spacing: 10px; page-break-inside: auto; font-size: inherit; @if $debug { background-color: #8bf0d7; } tbody { break-inside: auto; } tbody tr { page-break-inside: avoid; page-break-after: avoid; // INFO: this property if tables can break inside (between TRs) margin: 2px 0; ...
Developing
The isolated approach provided a pleasant developer experience, allowing the team to utilize familiar web tools and instantly preview the styled HTML page in the browser. We included a script in the package.json file for this purpose. However, the iterative process of developing the CSS, HTML, and data is only about 90% accurate because the browser doesn't inherently display print media-specific properties, such as page breaks. While the print view can be used to some extent, it often necessitates an additional testing step.
{ "name": "@exxcellent/a-pdf-template", "version": "1.0.0", "main": "build/index.js", "scripts": { "test:html": "mkdirp build && mustache ./test/example-data.json src/template-file.html > build/report.html", }, }
Testing
To test the PDF appearance, we called our generic converter service with the data and template. We achieve this by making an HTTP POST request, e.g. curl. As the data is in JSON format, providing various test data was simple.
Additionally, for an external supplier, we integrated their template's PDF creation process into our GitLab CI pipeline. This ensured we can verify the process and results using the same approach.
pdf-integration-test: image: gitlabserver.exxcellent.de:9999/exxcellent/converter-service:latest stage: test services: - name: gitlabserver.exxcellent.de:9999/exxcellent/converter-service:latest alias: converter-service script: - curl --location --request POST 'http://converter-service:5001/pdf' --form 'html=@"./a-pdf-template/src/template.html"' --form 'json=@"./a-pdf-template/data.json"' --form 'css=@"./a-pdf-template/src/template.css"' -o report.pdf artifacts: paths: - report.pdf only: - development
Best practices
Embedding fonts and images
Images contained in the html are referenced by their url and must be accessible from the converter service. Our images were stored in the headless cms, so we had no problem with it. Fonts on the other hand were not stored in the cms, because those are usually available via a CDN or locally stored on a web server. We simply did not have this available and placed the fonts in the converter service (mapped into the docker image as volume).
Performance
Creating PDFs takes time - literally. In our public web portal the number of downloads is unknown but the available PDFs known. Our solution was to create and store the pdf for all static content and only render dynamic data, such as personal lists on demand as PDF. For this purpose we deployed another isolated converter service.
Restrictions
-
Limited CSS Support: WeasyPrint doesn't support all CSS properties, selectors and features. Certain CSS properties and styles don't render as expected or may be ignored altogether. In another project we were surprised how PrinceXML is handling those features much better.
-
Complex Layout Challenges: Complex layout requirements, such as multi-column layouts, complex positioning, or intricate page structures is challenging to achieve with WeasyPrint. Most of the time you need the skills to workaround the issue.
-
Accessibility: With Weasyprint it is currently limited, e.g. manipulating the document metadata such as the language, pdf tagging and text alternatives on images.
Conclusion
This article highlights the enduring relevance of PDFs, even after three decades. We explored three primary methods of PDF creation, each with its own set of advantages and limitations. Our focus was on showcasing a solution utilizing the HTML+CSS approach for PDF generation as a generic service. This approach is particularly advantageous for teams centered around web development, as it allows them to leverage existing skills, tools, and workflows seamlessly.
So for the public web portal case study the converter service proofed to be a valid choice. The team of web developer swiftly produced initial results, but challenges arose when addressing how the web widgets would be displayed in the PDF, considering space restrictions and page breaks. These discussions mirrored those encountered during responsive web layout specifications for various devices. So in conclusion print media is another device and some css media queried print styles were never able to fulfill the requirements. Regarding the performance weasyprint is cpu intensive and slow. Generating the PDFs on-stock instead of an on-demand approach helped balancing the performance impact.
API-based approaches, such as openPDF, require programming skills but offer fine-grained control over PDF creation and manipulation from our experience. XSL-FO approaches, such as Apache FOP, excel in precise layout control and involves in a steeper learning curve due to the XSL-FO markup language and required tools. Ultimately, the choice depends on the project requirements, developer expertise, and desired balance between ease of development and customization capabilities.
Image sources
The cover image used in this post was created by Edmond Dantès under the following license. All other images on this page were created by eXXcellent solutions under the terms of the Creative Commons Attribution 4.0 International License